File Comparer is a free portable utility to compare all the files in two directories / directory trees / drives.
It can compare:
The differences are listed on screen and written to a more detailed tab delimited text file (that can be analysed further in Excel).
Network (UNC) paths are supported.
The utility is read only (i.e. makes no changes to files).
Comparing the differences between a failing Hard Disk (E:\) and a recent backup copy of the disk (T:\). The utility can scan all the files in the E drive (or a single folder / sub-set of folders) and compare to the equivalent set of files / folders on drive T.
This example is described in more detail below.
The utility is written against .NET 3.5. It supports the smaller client profile or the full framework.
When comparing only file sizes and/or last modified dates, the utility requires a tiny amount of memory to run.
When comparing file contents the utility requires about 550MB memory to run. This is used to allow the disks to read-ahead and keep the comparison process moving quickly.
Current version, v1.0 (30th Sept 2013), 51kb.
Please send any feedback to:
feedback at filecomparisonutility.cbailiss.me.uk
(please re-assemble the email address - I have written it like this on this page to reduce junk email).
The results file contains a line for each file that has been compared. The results file contains the columns described below. The example values are taken from a single line in the results file for an example run where drive E was being compared to drive T.
Note that the columns marked * in the table below are only populated if the contents of the files are being compared. If only the file sizes and/or dates are being compared, then these columns are present but empty.
| Column Name | Example Value | Explanation |
| RELATIVE DIR | TFS Backup | The relative path to the file being compared, within each of the two folders being compared. |
| FILENAME | BackupSets.xml | The name of the file being compared. |
| FULL PATH 1 | E:\TFS Backup\BackupSets.xml | The full path of the file in folder 1 (referred to as "file 1" below). |
| FULL PATH 2 | T:\TFS Backup\BackupSets.xml | The full path of the file in folder 2 (referred to as "file 2" below). |
| FULL EXISTS 1 | Y | Y if file 1 exists. |
| FULL EXISTS 2 | Y | Y if file 2 exists. |
| FILE SIZE 1 | 13156 | The size of file 1 in bytes. |
| FILE SIZE 2 | 12231 | The size of file 2 in bytes. |
| LAST MODIFIED 1 | 30/09/2013 07:54 | The date file 1 was last modified. |
| LAST MODIFIED 2 | 20/09/2013 09:36 | The date file 2 was last modified. |
| CONTENT DIFFERENT * | 2419 | How many bytes are different between file 1 and file 2. |
| CONTENT EQUAL % * | 81.61295227 | The percentage of file 1 and file 2 are the same. |
| POSITION OF FIRST DIFFERENCE * | 203 | The position in the two files where the first difference occurs. |
| COMPARISON RESULT | DIFF: Size (925 bytes) | The overall result of the comparison. Possible values are SAME, DIFF (reason) and ERROR. |
| FILE 1 ERROR | Errors relating to a specific file are highlighted here and on the Errors tab (some errors relate only to directories and not specific files - these appear only on the Errors tab). | |
| FILE 2 ERROR |
The file contents comparison compares byte-by-byte, i.e. does byte 1 of file A = byte 1 of file B, repeating until the end of the files. Note this is different to the comparison performed by some text editors which will line up lines from different places in the file.
For example, consider the two files:
| FILE 1 | FILE 2 |
| 12345 67890 abcde | 12345 abcde fghij |
For these two files (assume UTF-8 encoding):
This method of measuring the difference between two files is different to how text editors (e.g. for programming) measure difference (which typically look for inserted lines, modified lines, deleted lines, etc).
The utility is multi-threaded:
The memcmp optimisation setting enables the actual in-memory comparison of the file contents (i.e. once read from disk) to use the assembly optimised memcmp routine from the c runtime libraries in windows, which is about 50-100 times faster than the .NET managed code equivalent. If this optimisation isn't used, the file contents comparison is significantly slower (i.e. it becomes CPU bound and data is read from the disks at a much slower rate).
On the Results tab, the four numbers at the top right provide an instantaneous view into the queues between threads when file contents are being compared. Files are read from the disk in chunks, each chunk being a maximum of 1MB in size. Thus a file is at least one chunk long. The first two numbers in this box are the size of the data queue in MB and file chunks (of data already read from disk) between the thread reading from folder 1 and the comparison thread. The third and fourth numbers are the same two numbers for the queue between the thread reading from folder 2 and the comparison thread.
This architecture is able to drive consumer-grade disks to very close to their maximum sequential read IO rate when comparing the contents of files of 1MB and over.
On enterprise-grade storage (i.e. more spindles supporting each drive) the storage won't be running at it's maximum capability. Further development work (to add additional multi-threading) could get closer to this, but it would add complexity (I did mention this utility was free, right?). Also, issuing parallel IO requests would very likely reduce the throughput from consumer-grade storage (as it would result in more head movement, so increased seek time, etc).
This was a real example (from my home PC).
We have a failing data disk (E:) that we don't trust the contents of any longer (some odd noises and data retrieval delays). We also have a recent backup of this disk restored (as T:). Drive T contains data we trust, but there a few changes not reflected in it that we want to see if we can get from drive E before we remove it. A somewhat painful proposition.
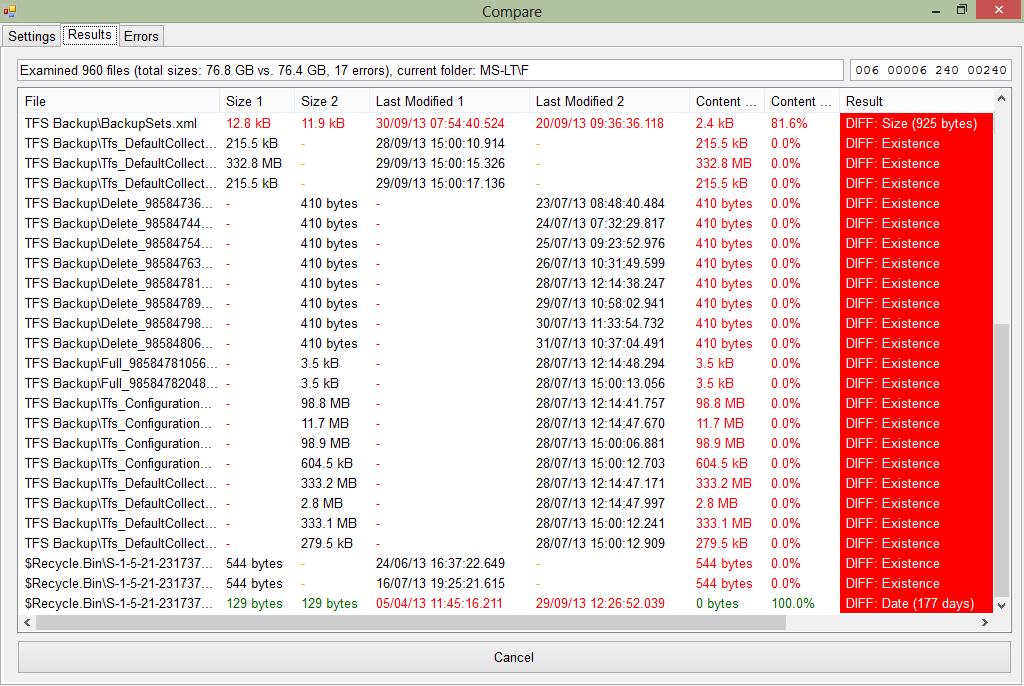
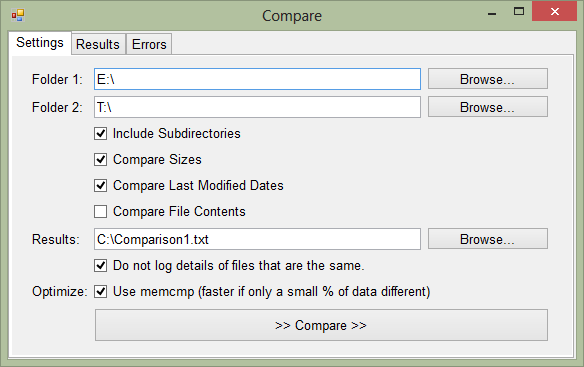
So, we want to compare the contents of drive E and drive T. Firstly, let's just compare file sizes and dates (much quicker than comparing contents and often this may be sufficient):
So, we have some differences. TFS Backups from different dates. Differences in the recycle bin. The list goes on. Further below are some files that are missing from drive T that luckily are still accessible on drive E so we can copy those off.
On the Errors tab, let's take a look at the errors.
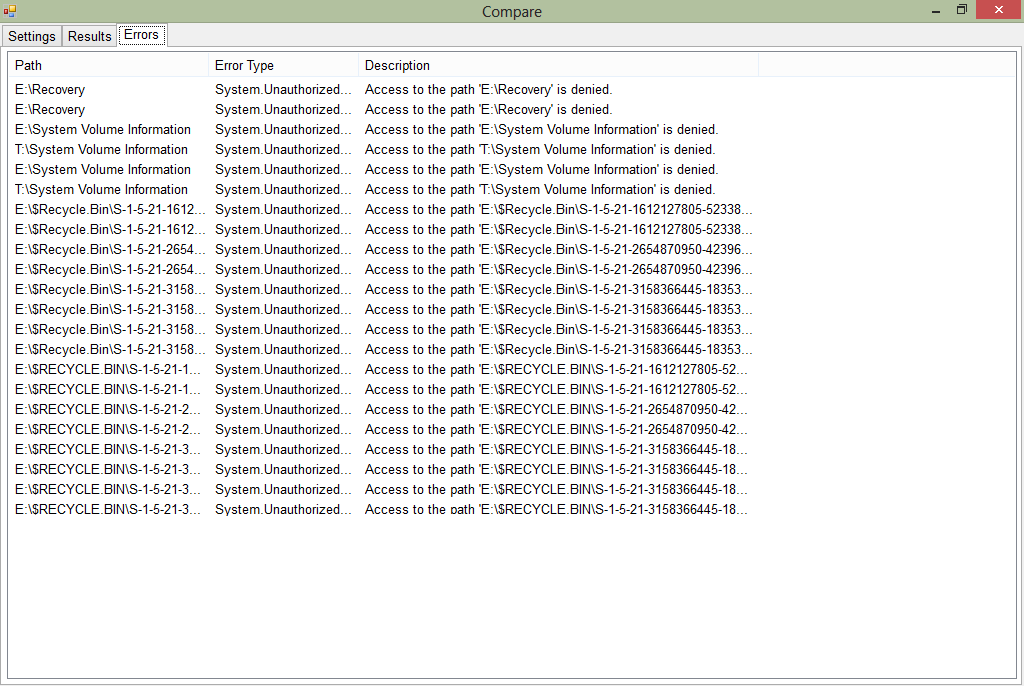
Looking at these, they can all be ignored. Some system folders that the utility can't access (but no user data in those). Similarly in the recycle bin. A note that a VM can't be compared so we need to check that manually. All OK really.
That should be sufficient to ensure we have got our data back in one place. This is the end of the data restoration process, but read on a little more for another use of the utility.
Now, the disk failure on drive E is a bit of a mystery. I spotted it by seeing increasing sector failure counts in the great GSmartControl utility. However, the drive still appears to be generally working and the drive's own SMART reporting hasn't highlighted any problems. Even the Western Digital Diagnostic tool is reporting the drive is healthy.
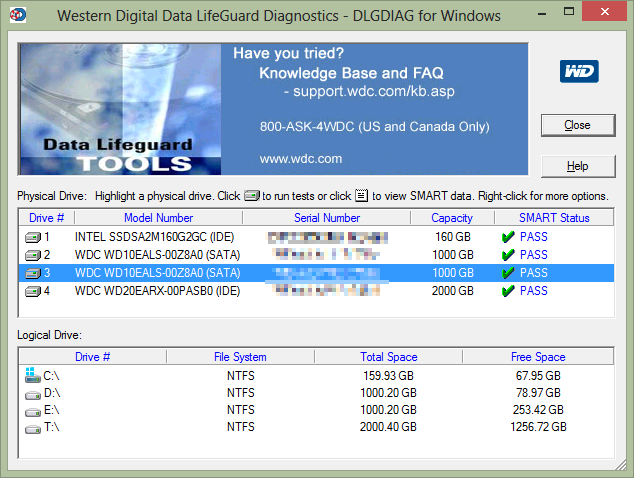
However, GSmartControl is pretty trustworthy. Also, the windows chkdsk / scan disk utility is behaving erratically with the drive (sometimes completing successfully, sometimes not). So, is it really broken? Let's compare our newly complete data on T with the data on E.
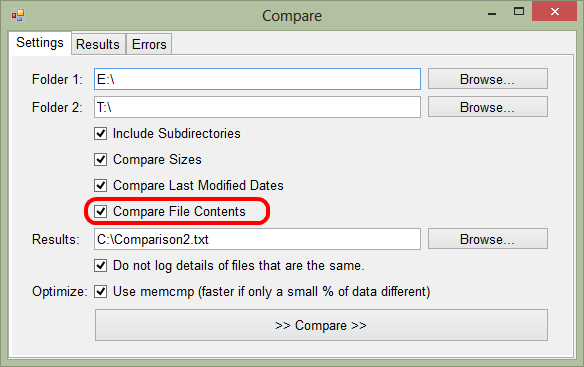
So, second run of the tool, this time also comparing file contents:
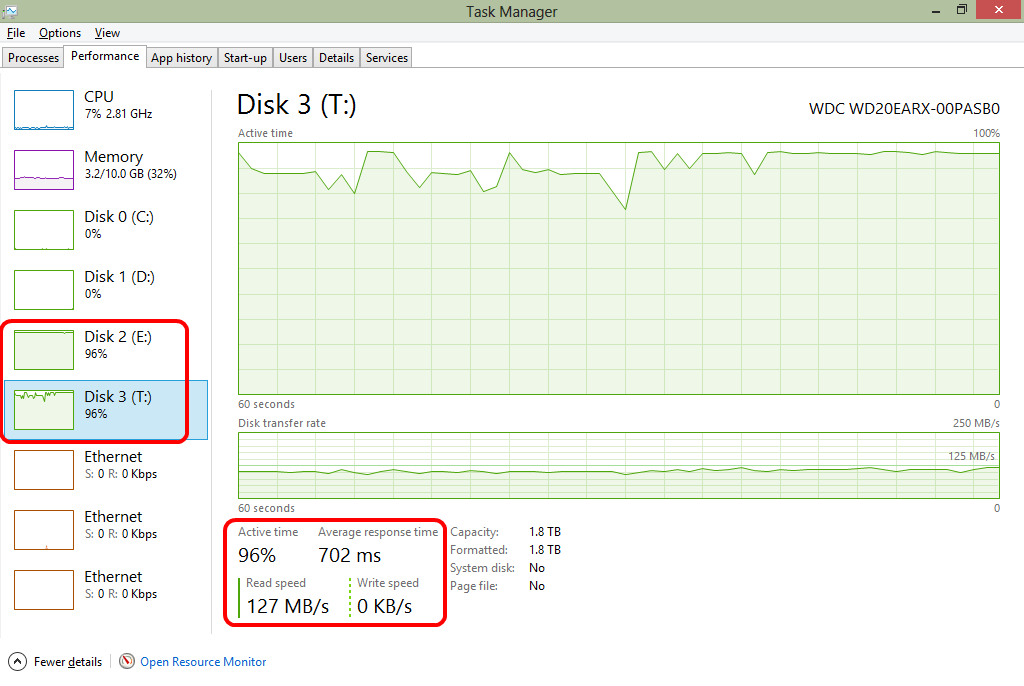
Interestingly, there are some long pauses when trying to retrieve data, with task manager looking particularly ominous.
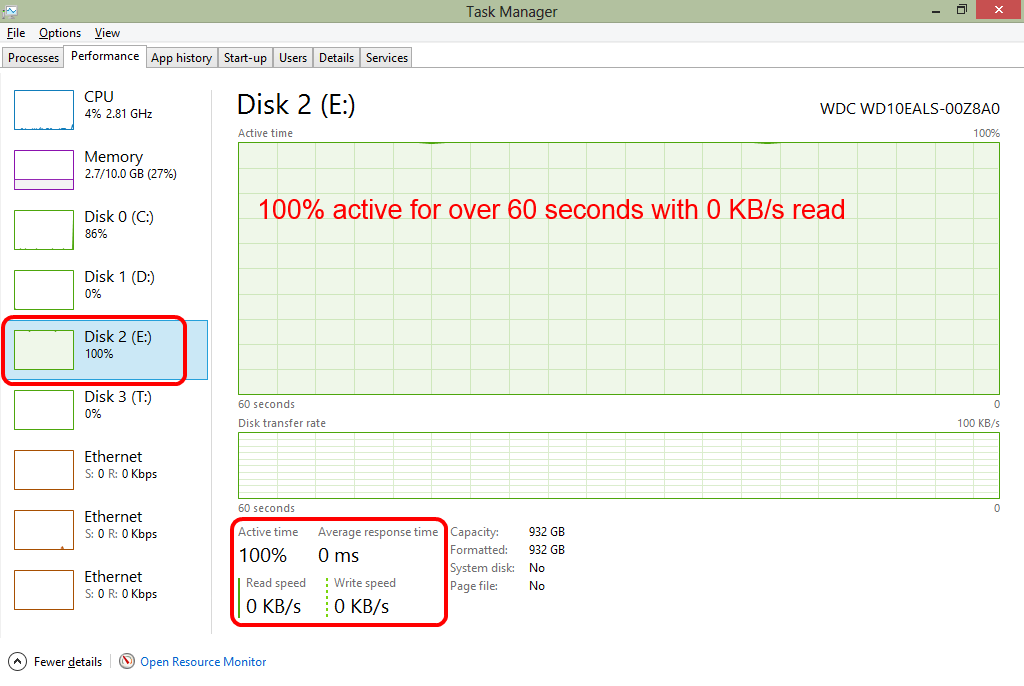
The results tab is highlighting some unexpected and unexplained differences in file size:

Also, a few dozen additional errors are showing up on the Errors Tab (showing the first few here):

This is strongly suggesting the drive is now defective and shouldn't be trusted.